Unlocking Hidden Data Relationships: A Deep Dive into Efficient Correlated Data Discovery
June 17, 2025
We live in an era of unprecedented data generation, from scientific research to government records and business operations. This vast availability offers great opportunities for analysis and discovery, but it also raises a significant challenge: how do we identify the right data in such immense repositories?
In my PhD research, I focused on the challenging but essential task of discovering correlated data across different datasets. Now, one year after completing my PhD, my thesis has been awarded a 2025 ACM SIGMOD Jim Gray Doctoral Dissertation, Honorable Mention. If you are curious and have the time, you can read the full thesis here: "Efficient Algorithms for Correlated Data Discovery". Otherwise, keep reading if you just want a TL;DR.
The Challenge: Finding the Right Data for Better Machine Learning
Imagine you have a dataset, perhaps daily taxi trip counts in a city, and you want to find other datasets that could help explain or predict these counts. You might look for datasets covering the same dates or locations (like weather data or demographics). Finding datasets that can be joined based on common columns (like dates or zip codes) is a known problem, but it often yields too many irrelevant results. This is because many datasets that can be joined are completely unrelated to the problem at hand. Moreover, joining every potential dataset just to see if it contains useful, correlated information is incredibly time-consuming and computationally expensive, sometimes prohibitively so. This need was identified while building Visus, an interactive AutoML system that allowed users without machine-learning expertise to build effective models. When we started this research, existing data discovery systems relied on simple keyword searches over metadata, which isn't expressive enough for these complex needs and can be limited by incomplete or inconsistent metadata.
Auctus: A Search Engine for Data Discovery and Augmentation
As part of the early work in my PhD, we developed Auctus (auctus.vida-nyu.org), an open-source dataset search engine designed specifically to address some of these limitations [VLDB 2021]. Auctus goes beyond simple keyword search by:
- Ingesting data from various sources, including open data portals (like Socrata, Zenodo) and user uploads.
- Automatically profiling datasets to extract richer metadata directly from the content. This includes detecting data types (like categorical, numerical, spatial, temporal) and computing summaries.
- Supporting richer queries, allowing users to search not just by keywords but also by spatial or temporal constraints, required data types, or even finding datasets that can be joined or concatenated with an input dataset.
- Providing an interactive interface to explore search results, view dataset summaries and statistics, and even perform data augmentation operations directly.
Developing Auctus highlighted the need for even more advanced techniques, particularly for efficiently finding datasets that are not just joinable, but also correlated. This experience directly motivated the subsequent research contributions focused on Join-Correlation Queries and sketching algorithms to support answering such queries efficiently.
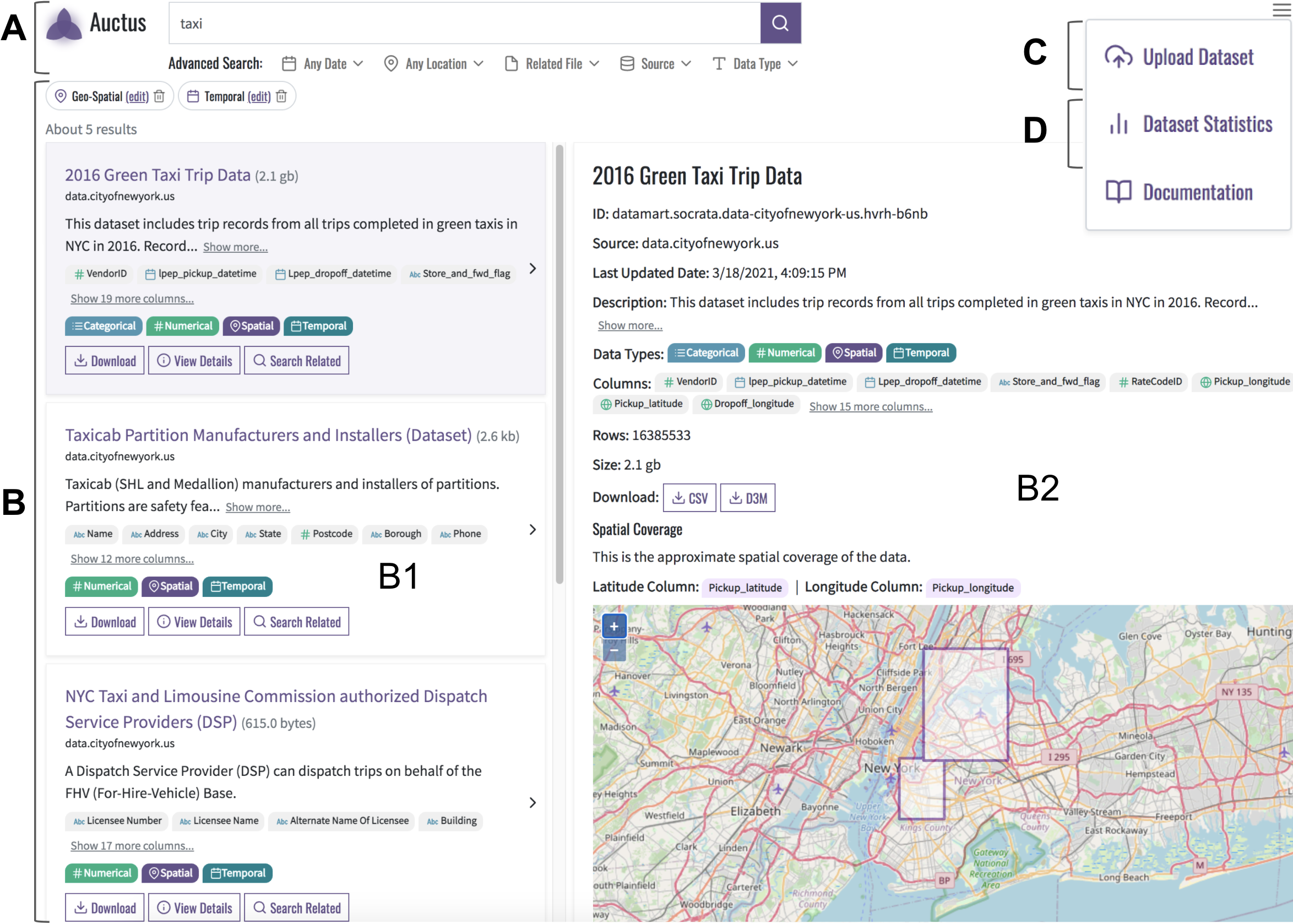
Figure 1: Auctus’ user interface: (A) keyword and filter-based search box; (B) search results; (B1) dataset snippets; (B2) dataset summary; (C) dataset upload; (D) dataset collection statistics.
Finding Data that are Joinable AND Correlated
The next step was to precisely define the type of search needed for correlated data. I introduced and formalized the concept of Join-Correlation Queries (JCQs) [ACM SIGMOD 2021].
In simple terms, a JCQ asks: Given my table (e.g., taxi trips TY with trip counts Y and join column KY like 'Date' or 'ZipCode'), find other tables (TX) in a large collection that:
- Can be joined with my table
TYon our common columnKY. - Contain a column
X(e.g., 'Rainfall' or 'Population') that is strongly correlated with my target columnY('NumTrips') after the join is performed.
This query type directly addresses the need to find datasets that can be combined (via a join) and are likely to contain meaningful predictive or explanatory signals.
For practitioners, here's another way to think about it using Python libraries: Imagine you have your primary DataFrame (TY) with a target variable (Y) and a key column (KY). You want to find other DataFrames (TX) scattered across a data lake. A JCQ aims to identify a TX such that if you were to perform a pandas.merge(TY, TX, left_on='KY', right_on='KX'), the resulting merged DataFrame would contain at least one column (X) originating from TX that shows a strong statistical relationship (like high correlation or mutual information) with your original target column Y. In machine learning terms, you're looking for tables TX which, after merging, provide a new feature X that would help a scikit-learn model trained using .fit(Y, [X]) to predict Y. JCQ automates the discovery of tables TX that satisfy both the merge possibility and the potential for a good feature fit.
Unfortunately, naïve solutions for such queries in large data repositories can be way too expensive!
Summarizing Data for Efficient Join-Correlation Estimation
The main bottleneck is the cost of actually performing all those potential joins, so we must avoid them if we need efficient solutions. The core idea of my work was to use data sketches – think of them as highly compressed, intelligent summaries or fingerprints of the data columns.
Instead of working with the full datasets, we can pre-compute these sketches for all tables in a repository. Then, at query time, we can compare the sketches of the query table and candidate tables to estimate the correlation between columns without performing the full join. Additionally, sketches can be indexed and queried using systems like Elasticsearch to quickly find potential joinable tables. This makes the process significantly faster.
My research developed specific sketching algorithms tailored for this:
- CSK (the 'original' Correlation Sketch) [ACM SIGMOD 2021]: The initial method designed to estimate correlations (like Pearson's or Spearman's) across unjoined tables. It cleverly uses hashing to ensure that sketches of joinable tables have overlapping elements, allowing for correlation estimation on this overlap. The core technique used here is known as coordinated sampling.
- TUPSK (Tuple-based Sketch) [IEEE ICDE 2024]: An improvement over CSK, specifically designed to better handle real-world data complexities like LEFT joins over repeated join key values (common when joining tables for machine learning). TUPSK ensures a uniform sampling of the data, reducing bias in estimations, especially when join keys are skewed.
While both algorithms can be used to estimate more complex, non-linear relationships using measures like Mutual Information (MI) over numerical and categorical data, the original paper [ACM SIGMOD 2021] focused on traditional correlations over numerical data, whereas the [IEEE ICDE 2024] paper focused on MI over both data types.
A key challenge with using estimates is dealing with potential errors – sometimes, a sketch might make a weak correlation look strong just by chance. My work also developed methods to create confidence bounds for these sketch-based estimates and designed scoring functions that rank potential results by considering both the estimated correlation strength and our confidence in that estimate, pushing more reliable results to the top.
Weighted Queries and Even Faster Indexing (QCR)
Another issue that arises when obtaining new features via table joins is that unmatched join keys lead to missing data values in the new feature X. To address this issue, we introduced Weighted Join-Correlation Queries in IEEE ICDE 2022. This approach allows users to adjust their search criteria by specifying the importance of joinability versus correlation strength. This way, they can strike a balance between predictive power and the presence of missing data. Depending on your needs, you might prioritize a strong correlation even if the join overlap is not perfect, or you may find a reasonable overlap to be more critical.
While the method method discussed above allows to answer this query, we wanted to make these queries even faster and more accurate! To do so, we developed a novel hashing scheme called QCR (Quadrant Count Ratio). This method cleverly encodes information about both the join key and whether the numerical value falls into a positive or negative correlation quadrant (relative to the mean) into a single hash term. This allows us to build an index (the QCR Index) where finding tables that are both joinable and correlated is reduced to a fast set overlap search, retrieving candidates in a single step rather than the two-stage (joinability then correlation) approach needed previously. As before, all of these terms can be indexed in systems such as Elasticsearch or relational databases, enabling rapid searching across large collections. Experiments showed this QCR approach significantly improves recall (finding more relevant tables) and ranking quality, often using less storage space than the previous sketch-only methods.
Why Does This Matter?
These algorithms provide practical tools for navigating massive data collections. They make it feasible to automatically discover features that can significantly improve machine learning models, as demonstrated in use cases like predicting taxi demand or identifying protein measurements linked to cancer gene mutations. For instance, the plots in Figure 2 below show examples of gene prediction models that can be trained with automatically discovered features, and achieve comparable performance to models built using biological domain expertise. By estimating relationships efficiently before performing expensive data integration steps, these methods save valuable time and computational resources for data scientists and researchers (Note: see Chapter 7 for details, as these results do not appear in any of the previous papers!).

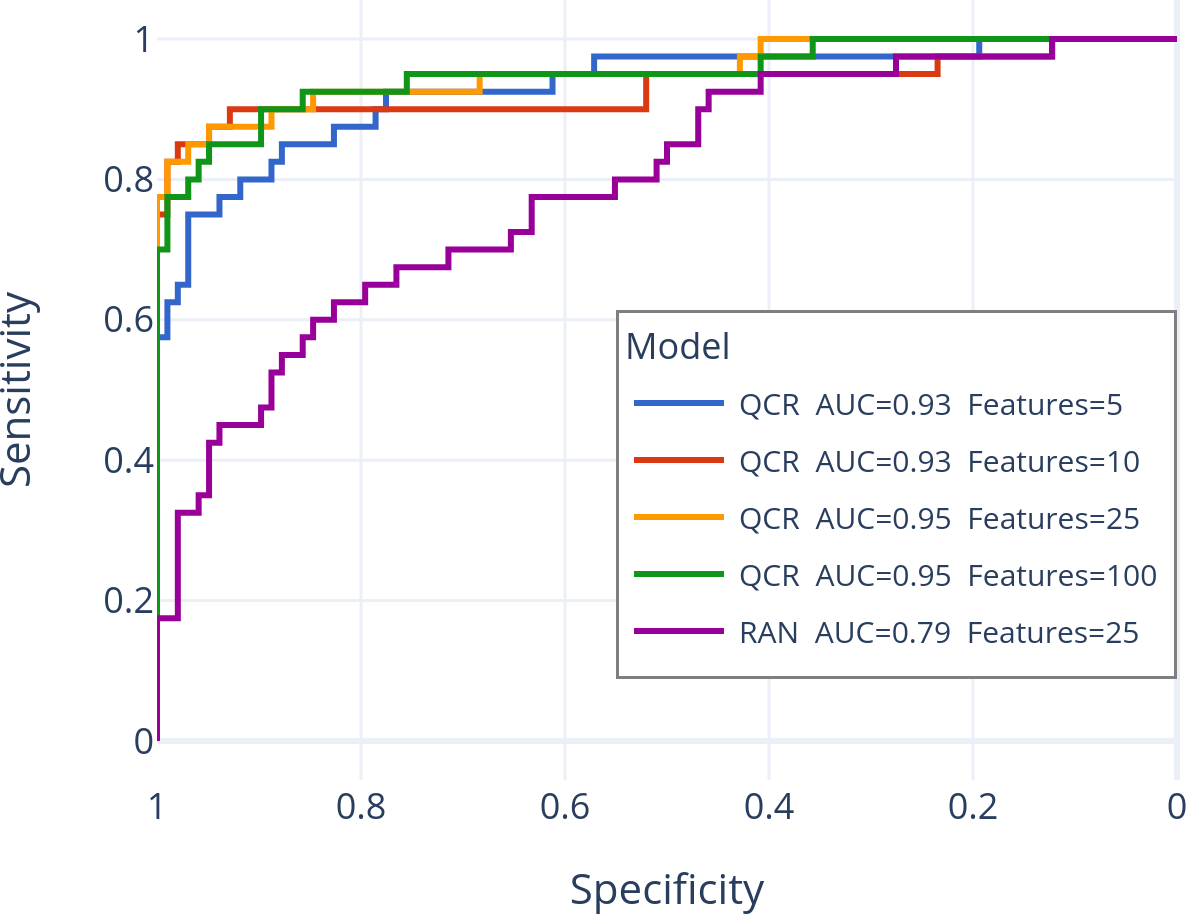
Figure 2: Left: Models from Dou et al. [Cancer Cell, 2023] that use t-tests and biological knowledge to select the top 10 best features in each model. Right: Models built using the top-{5, 10, 25, 100} features discovered automatically using a QCR index.
Wrapping Up
The explosion of data requires smarter tools for discovery. My PhD work contributes new algorithms and formalisms to efficiently find correlated information hidden across disparate datasets. By leveraging the power of sketching and specialized indexing, we can move beyond simple keyword search towards more powerful, data-driven discovery, ultimately helping us make better sense of the complex world reflected in our data.